C#でコマンドラインの起動オプションをパースする処理はその都度書いてたんだけど、一度、汎用的に使えるものを書こうとした時期もあったんですが、型を意識しないといけないので真面目に書こうとすると複雑で挫折してました。
妥協して、Dictionary<string,string>に全部格納して、使うたびにそれぞれ欲しい型に変換する処理書いてしまえばいいや、と思い、とりえあえず書く。
Programing…
Vite はじめました編
javascriptでvueやreactみたいなフロントエンドフレームワークを使うほどのものを書いてるわけではないのですが、さすがに excel とか pdf とかブラウザでアーダコーダするようになってくると、javascriptのコードを書く量も多くなってJavaScriptライブラリの依存関係も多くなり、こりゃいかん!ってことで、今更ながら Vite を使いだしました。
で、困った問題が一つ、jQuery 自体は、import $ from ‘jquery/dist/jquery.slim’; とかでインポートして使えるんだけど、jQueryプラグインは、ほとんどの場合 window.jQueryが存在していることが前提なので (jQuery.fn に登録する) 、いくら Vite でも、jquery ブラグインを import とかで読み込んでもエラーで使えません。
で、 インポートした jquery を window に注入して、scriptタグを生成することで何とか回避するようにしました。
以下、jQueryのHTMLエディター Trumbowyg を使用するまでの手順。
Vite で プロジェクトにディレクトリを作る。
# テンプレートに valilla を選択、jquery,bootstrap,trumbowyg をインストール >> npm create vite@latest sample -- --template vanilla >> cd sample >> npm i >> npm i jquery bootstrap trumbowyg
npm create で生成された index.html や 画像、main.js などは必要ない、というか書き換えるので削除する。
index.html,main.js を用意
とりあえず、簡易的に index.html, main.js を書く。
index.html には、最低限のものだけ、このHTMLファイルに main.js をスクリプトタグで書いておく。
bootstrapとかの読込とか、jqueryとか、ブラグインとかは全部 main.js に書いて Vite にお任せするので、html に書く必要はない。
main.js は type=module で読み込む↑↑↑
とりあえず、↓のような感じ。
開発用サーバー立ち上げとビルド処理
Viteは 開発用のwebサーバーも内蔵しているので、とにかく開発環境を構築するのはホントにラクちん。
# 開発時は以下でビルトインサーバー立ち上げ、ファイルを書き換えると瞬時に反映される。 >> npm run dev # 公開するときは、ビルドする。デフォルトだと dist ディレクトリが作られる。 >> npm run build # ビルドされたものを確認するためのビルトインサーバー立ち上げ >> npm run preview
Vite自体は vue とかのフロントエンドフレームワークを使う前提なんでしょうけど、フレームワークを使わないVanillaJSやjQueryを使う小規模の開発でも簡単にはじめられるので積極的に使っていこうと思います。
.NET 8.0 でWinFormsアプリ
動画の変換に ffmpeg をよく使ってます。ffmpegは便利なんですが、いかんせんコマンドをポチポチ入力しないといけません。
毎回決まったようなオプションを入力するのが手間で、バッチファイルを作成してできるだけ入力を抑えていたのですが、それもめんどくさくなって、ffmpeg の GUIを探してみましたが・・・あんまり見つかりません。
動画の変換の有名どころは、HandBreakですが・・・最近仕事も落ち着いて暇になってきたので、ffmpegのコマンドラインを組み立てて実行するだけのGUIを作ってみよう・・・と 久しぶりに Visual Studio 2022 community を起動して作り始めました。
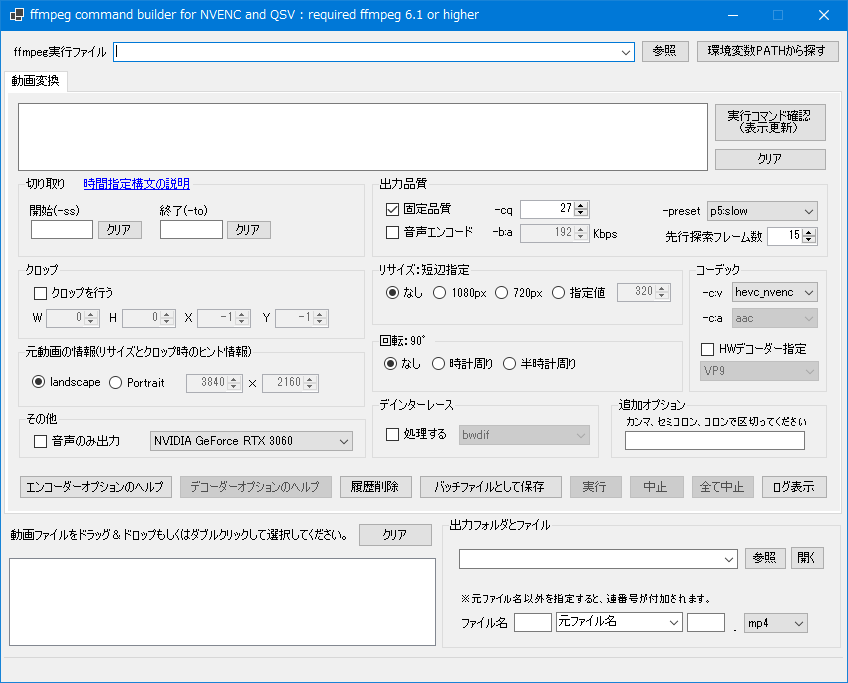
Windowsでしか使わねーし、とか思って .NET Framework 4.8 の WinForms で作り始めたのですが・・・.NET Frameworkもいつまでサポートされるか分からないので、途中から 最新の .NET 8.0 の WinForms に変更。C#進化しすぎてて、迷う迷う。
List<T>とか配列の初期化にJavaScriptやperlみたいに、[] でできるのにちょいビビった。
ランタイムフレームワークを変更して気付いたのですが、フォームのデザイン画面のプロパティーで、Application Settings のバインディングする項目が消えちゃってますね・・・.NET Framework 4の時は、テキストコントロールとかチェックボックスのチェック状態を App.configファイルで保存して、Settings.Default経由でコントロールにバインドしてたんですが・・・.NET 8.0 になってGUIのプロパティで設定できなくなったのかなぁ???
しょうがないので、Formのコンストラクタで InitializeMember()メソッドをコールした後・・・
TextBox1.DataBindings.Add("Text", Settings.Default, "TextBox1Text") ;
CheckBox1.DataBindings.Add("Checked",Settings.Default,"CheckBox1Checked");
とかで、できそうだ。なんか別に方法があるかもしれない。よく分からないが、WinFormsもまだまだ使える💦
とりあえず、次のコミットで直そう。Gitは大体慣れてきたが、githubは、複雑過ぎてイマイチ分からん。普通のパスワードが使えなくなって最初、わからーーーん、どうやって認証するねーーーーん!!! ってなって焦った(笑)
関係ないけど、やっと 仕事で使っているVCS環境を Subversion から Git に移行できた。一部 Subversion に依存しているところはおいおい直すことにした。 リモートのリポジトリの置き場を Githubにはできないので Subversionで使っているVPSに同居。分けんといかんなぁ。。。
JavaScript Cache APIと有効期限
公開されている色んなWeb APIを使うと、簡単にデータを引っ張ってこられるので、便利ですよね。
ただ、有料のAPIとかだと、むやみにやたらにAPIサーバーにリクエストを出すとコストがかかってしまい、なんとかブラウザでlocalStorageとかでキャッシュさせたい! と思ってました。
最近のブラウザはCache APIでキャッシュを完全にコントロールできるようになっているようで・・・知らなかい事ばかり💦
https://developer.mozilla.org/ja/docs/Web/API/Cache
Cache APIは、fetchなどで得られたリクエスト(URL)とレスポンスを対にしてキャッシュしてくれるものの、自動的にキャッシュが削除されたり、とかいうのはできないみたいで、キャッシュを更新したければ、自分でそういう実装をしないといけないようです。
はじめは、fetchで得られたレスポンスにキャッシュした時のUNIX時間をセットして、使うときに、現在時刻と比較してやれば・・・と簡単に思っていたんですけど、fetchから取得したレスポンスのヘッダ情報はリードオンリーなので、書き込めず。。。
ググると、fetchで取得したレスポンスの情報をコピーして、新しいレスポンスオブジェクトを作って(new Responseして)それをキャッシュさせればいいみたい。
とりあえず思いつくまま、コードを書いた(エラーチェック無し)↓
これを
//もちろん、異なるoriginのURLの場合は Access-Control-Allow-Origin ヘッダに対応してないといけないが・・・
const url = 'https://hoge-hoge.com/get?xxx=yyy';
// window.caches チェックして対応していない場合は、通常の fetchを使用する。
const json = ('caches' in window) ? await cachedFetchJson(url) : await fetchJson(url);
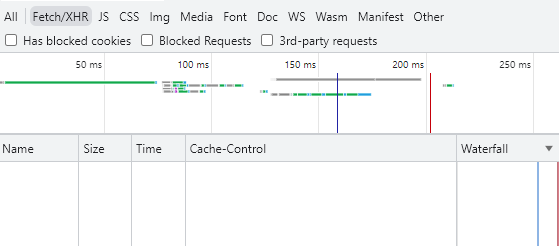
とりあえず、1回目はfetchが走り・・・
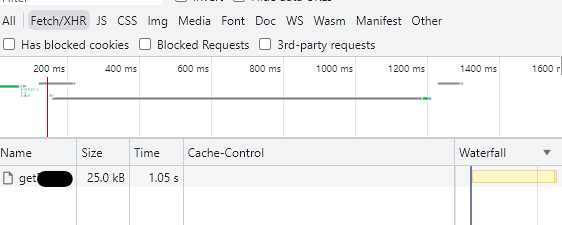
ブラウザのキャッシュを無効にしているにも関わらず、2回目は、fetchは走っていませんでした。
ブラウザでPDFファイルの画像化
持病の影響で急性腎不全を患い、少しばかり入院していました。はぁ~、健康って大事ですよねぇ。。。
というのは、さておき。
コーディング・メモです。
PDFファイルの画像を生成するため、アップロードしたPDFファイルをサーバーで(具体的には ImageMagickで)処理していました。
周知のとおり、ImageMagickでPDFファイルを処理するとセキュリティー云々があってごく限られた場合に使用するようにしていました。
ImageMagickはいいですね、もう画像関連の処理は全部コイツに任せたいぐらいですが、4~5年前に脆弱性に関する情報がいっぱい出て使うのをためらっています。2022年末になってもまだ同じ状況なのでしょうか?よく分かりません。
というわけ・・・でもないのですが、サーバーサイドでImageMagickに頼らず、ということになるとImageMagickの代替を探すか、自作するしかありませんが、画像のアルゴリズム他に関する知見はほとんどないので自前でなんとか、というのはできない。となると、クライアントでどうにかするしかありません。
幸いにも、最近のウェブ環境ではJavaScriptでどうとでもなります。
PDFフォーマットの解析・表示には、MozillaさんがPDF.js を公開してくれてます。今更ですが。
A general-purpose, web standards-based platform for parsing and rendering PDFs.
PDF.js
これを使うと、File,Blobなどで取得したPDFデータを HTMLに書いたcanvas要素にレンダリングしてくれます。
canvas要素にレンダリングしてくれたら、あとは canvas要素の画像を取得して Blob に変換してあげて、サーバーにPDFとともに生成した画像を送信してやれば、サーバー側で重い処理を走らせずに済みます。
上記サイトにサンプルがあるので、チョチョっといじれば、簡単に実装できる、いい時代です。
最初、ダウンロードしたファイルのどれが必要なのかよく分かんなかったですが・・・、最終的に、以下のように buildディレクトリとcmapsディレクトリさえあれば、事足りるみたい。
.
└── pdfjs
├── build
│ ├── pdf.min.js
│ ├── pdf.sandbox.min.js
│ ├── pdf.worker.entry.js
│ └── pdf.worker.min.js
└── cmaps/*
とりあえず動作デモ
ソースを見れば大体何をやってるかは分かると思います。チョーカンタン。
input[type=file]要素でファイルを読み込んで、それをそのまま渡すと変換した画像のFileオブジェクトを返してくれるような関数を書いてみました。再利用しやすいようにとりあえずモジュールとして書いた。
これを、下記のようにコール。
ものすごく、簡単。